在新的业务中尝试使用 Meilisearch 实现搜索功能

前言⌗
因为业务中需要用到搜索功能,通过用户输入的文字查询同义、同音或近似的数据。虽然使用 MongoDB 的全文索引也可以实现,但是对于分词和纠错等需要自己单独取实现。
同时考虑到后期业务的扩张,肯定会有更多的数据和索引,于是考虑采用搜索引擎来解决。之前用过 Elastic Search 来处理业务日志等数据,搜索功能很强大,但是对于我们的业务来说它似乎太过于笨重了。不知道是否是对于 Java 的偏见😂 ,当然相比于今天的主角 Meilisearch 它确实显得过于臃肿,且性能上 Java 肯定远不如 Rust。
另外一个原因就是我们所使用的的框架 Laravel 的官方文档中全文搜索的章节也有提到 Meilisearch,这么一来集成它应该不是很难了。
部署⌗
# Meilisearch
## Data storage path
DATA_PATH=./data
## Environment variable, values: production or development
MEILI_ENV=development
## Log level, values: ERROR,WARN,INFO,DEBUG,TRACE
MEILI_LOG_LEVEL=INFO
## MEILI_MASTER_KEY must be set when MEILI_ENV is production, and MEILI_MASTER_KEY is optional when MEILI_ENV is development.
MEILI_MASTER_KEY=
## Sets the maximum size of the task database. Value must be given in bytes or explicitly stating a base unit.
MEILI_MAX_TASK_DB_SIZE=1Gb
目前 Meilisearch 还没有实现删除 Task 的 API 最好事先设置好 Task 的最大占用空间,否则在频繁更新数据的情况下,可能导致磁盘被大量 Task 占用!
services:
meilisearch:
image: getmeili/meilisearch:v0.26.1
restart: always
hostname: meilisearch
container_name: meilisearch
ports:
- 7700:7700
environment:
- MEILI_ENV=${MEILI_ENV}
- MEILI_LOG_LEVEL=${MEILI_LOG_LEVEL}
- MEILI_MASTER_KEY=${MEILI_MASTER_KEY}
- MEILI_MAX_TASK_DB_SIZE=${MEILI_MAX_TASK_DB_SIZE}
volumes:
- ${DATA_PATH}/meilisearch.ms:/data.ms
需要说明的是,当 MEILI_ENV 为 production 时,MEILI_MASTER_KEY 必须设置。虽然如此,但是建议在任何环境都设置上 MEILI_MASTER_KEY。
docker compose up -d
这里用的是基于 Go 开发的 Docker Compose,而非老版本基于 Python 的 docker-compose,升级请参考《升级 Linux 上的 Docker Compose 到 V2》
获取 API Keys⌗
curl -X GET 'http://localhost:7700/keys' \
-H 'Authorization: Bearer masterKey' | python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 655 100 655 0 0 87356 0 --:--:-- --:--:-- --:--:-- 93571
{
"results": [
{
"actions": [
"search"
],
"createdAt": "2022-04-15T09:01:04.670596731Z",
"description": "Default Search API Key (Use it to search from the frontend)",
"expiresAt": null,
"indexes": [
"*"
],
"key": "WC9L6J8q1601585056da2c18f1cec7a820fc69a507e2e159750d2e5ddef84d9bff1373d9",
"updatedAt": "2022-04-15T09:01:04.670596731Z"
},
{
"actions": [
"*"
],
"createdAt": "2022-04-15T09:01:04.668292104Z",
"description": "Default Admin API Key (Use it for all other operations. Caution! Do not use it on a public frontend)",
"expiresAt": null,
"indexes": [
"*"
],
"key": "9vGXfIKt601249b756efa25064922701b72979425bbddecab722dc1ded429eda37991f94",
"updatedAt": "2022-04-15T09:01:04.668292104Z"
}
]
}
这里的
masterKey就是在.env文件中设置的MEILI_MASTER_KEY。
可以看到 Meilisearch 会根据设置的 Master Key 自动生成两个 Keys,一个是用于"前端"应用直接请求 Meilisearch 的 API Key,这个 Key 只有 search 权限。
而另一个 Key 是 Admin API Key 可以用于后端导入数据或者其他管理用途,这个 Key 的权限很高,可以操作所有的索引。所以不要轻易暴露。
导入数据⌗
Meilisearch 支持 RESTful API,也有对应的 SDK,这里我们使用 PHP 的 SDK 和 Laravel Scout 实现索引的创建和数据的导入。
composer require laravel/scout
php artisan vendor:publish --provider="Laravel\Scout\ScoutServiceProvider"
composer require meilisearch/meilisearch-php:^0.23.1
composer require http-interop/http-factory-guzzle
注意
meilisearch/meilisearch-php的版本尽量与 Meilisearch 的容器镜像保持最新,不然可能存在一定的兼容性问题。
设置数据模型⌗
<?php
namespace App\Models;
use Laravel\Scout\Searchable;
class District extends Model
{
use Searchable;
/**
* Get the index name for the model.
*
* @return string
*/
public function searchableAs()
{
// 这里如果不想用模型的 table 或者 collectio 名称作为 index 的话,可以自己自定义名称
return 'district'
}
/**
* Get the key name used to index the model.
*
* Date: 2022/2/8
* @return string
* @author George <[email protected]>
*/
public function getScoutKeyName(): string
{
return '_id'; // 因为我这里使用的是 MongoDB,所以使用 _id 关联模型
}
/**
* Get the indexable data array for the model.
*
* Date: 2022/2/8
* @return array
* @author George <[email protected]>
*/
public function toSearchableArray(): array
{
// 设置需要被添加到 Meilisearch 的文档字段
return [
'code' => $this->code, // 行政区域编码
'fullname' => $this->fullname, // 行政区域名称
'spelling' => $this->spelling, // 行政区域英文拼写
];
}
/**
* Determine if the model should be searchable.
*
* Date: 2022/4/18
* @return bool
* @author George
*/
public function shouldBeSearchable(): bool
{
// 当行政区域的级别是一级和二级才导入到 Meilisearch 中,因为业务中只需要一级和二级城市支持搜索。街道等忽略。
return $this->level < 3;
}
}
当模型设置号以后,在项目中设置 config/scout.php 中的配置项:
# Meilisearch Engine
SCOUT_DRIVER=meilisearch
MEILISEARCH_KEY=
MEILISEARCH_HOST=http://localhost:7700
批量导入⌗
然后执行如下命令导入开始导入数据到 Meilisearch:
(x)# 从数据库中读取数据导入 Meilisearch
php artisan scout:import "App\Models\District"
(x)
(x)# 删除索引中的所有数据
php artisan scout:flush "App\Models\District"
更多相关功能请参照 Laravel Scout 官方文档。
验证搜索结果⌗
$items = District::search('东京')->get();
结果发现查询出来的数据中无法获取到一些 Meilisearch 的高亮信息,于是看了一下 SQL 的 Log,发现就是请求了 Meilisearch search API,然后根据所得的结果,将 ID 列表作为 whereIn 的条件查询出数据库中的模型。
这样的话我们还得自己实现匹配字词的高亮,但是这样会有个问题就是例如我搜索的关键词是东京,PHP 无法通过这两个字符去替换東京都中的東京。
直接调用 RESTful API⌗
尝试过使用 Laravel Scout 的搜索功能,发现无法满足高度自定义的需求,那么只能自己手动处理请求逻辑了。
curl --location --request POST 'http://localhost:7700/indexes/district/search' \
--header 'Authorization: Bearer masterKey' \
--header 'Content-Type: application/json' \
--data-raw '{"q":"东京","matches":true,"limit":10,"attributesToRetrieve":["code","fullname","spelling"],"attributesToHighlight":["fullname"]}'
请求体:
{
"q": "东京",
"limit": 2,
"matches": true,
"attributesToRetrieve": ["code", "fullname"],
"attributesToHighlight": ["fullname"]
}
- q: 搜索的关键词
- limit: 限制响应条数
- matches: 响应体是否包含
_matchesInfo - attributesToRetrieve: 设置响应体重包含的字段
- attributesToHighlight: 设置需要高亮显示的的字段,用于前段渲染
响应的结果:
{
"hits": [
{
"fullname": "東京都",
"code": "13",
"_formatted": {
"fullname": "<em>東京都</em>",
"code": "13"
},
"_matchesInfo": {
"fullname": [
{
"start": 0,
"length": 2
}
]
}
},
{
"fullname": "東京都千代田区",
"code": "13101",
"_formatted": {
"fullname": "<em>東京都</em>千代田区",
"code": "13101"
},
"_matchesInfo": {
"fullname": [
{
"start": 0,
"length": 2
}
]
}
}
],
"nbHits": 43,
"exhaustiveNbHits": false,
"query": "东京",
"limit": 2,
"offset": 0,
"processingTimeMs": 1
}
只要将这些数据返回给前端,由前端对 <em> 标签进行着色渲染,就可以实现高亮了。
索引的相关设置⌗
到这里就完了吗?并没有,在我们的业务中还希望对某个字段进行排序,但是我尝试在搜索的 API 中使用 sort 进行排序,得到的结果总是错误。
经过仔细的阅读 Meilisearch 官方的文档,无发现索引可以有如下几项设置:
- Displayed attributes: 属性的可见性设置;
- Distinct attribute: 设置相同属性时用于过滤的字段,可以参考官方文档给出的例子;
- Filterable attributes: 可过滤的字段设置,默认是 ‘’;例如,数据中存在状态字段,需要通过状态过滤是否展示,可以通过这个设置来实现;
- Ranking rules: 设置搜索引擎的权重,默认的是:“words”,“typo”,“proximity”,“attribute”,“sort”,“exactness”,“release_date:desc”;
- Searchable attributes: 设置可搜索的字段,默认是 ‘*’;例如,如果有些字段用于排序,比如价格,但不希望被搜索可以使用这个设置将价格字段排除;
- Sortable attributes: 设置可排序的字段,例如价格等字段;
- Stop-words: 设置不可搜素的词,例如一些没有任何意义的介词、代词等;
- Synonyms: 设置同义词
通过这些设置基本上能瞒住绝大部分的业务需求,请求速度上确实都是毫秒级响应,当然目前数据量也不是很大,性能还有待日后观察。
文档更新注意事项⌗
如果在对模型做 UPDATE 操作的时候,一定要将模型的 toSearchableArray 方法中定义的字段在查询的时候 SELECT 出来,否则会导致这个属性更新到 Meilisearch 中的值是 null!
Dashboard⌗
在管理 Meilisearch 的时候发现总是通过 Postman 或者 cURL 挺麻烦的,后来发现 Meilisearch 自带了一个简单的 Mini Dashboard。
当
MEILI_ENV为production时不可用!
这个不需要自己打包和部署,当 Meilisearch 服务启动后,可以通过浏览器直接访问,就会得到如下页面:
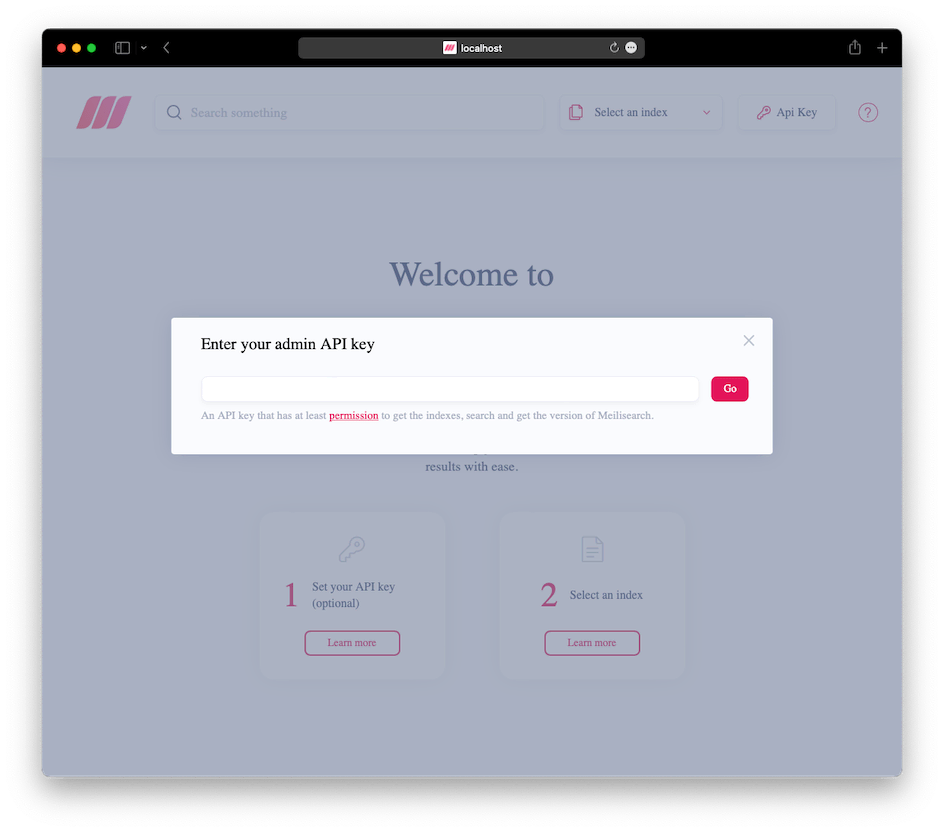
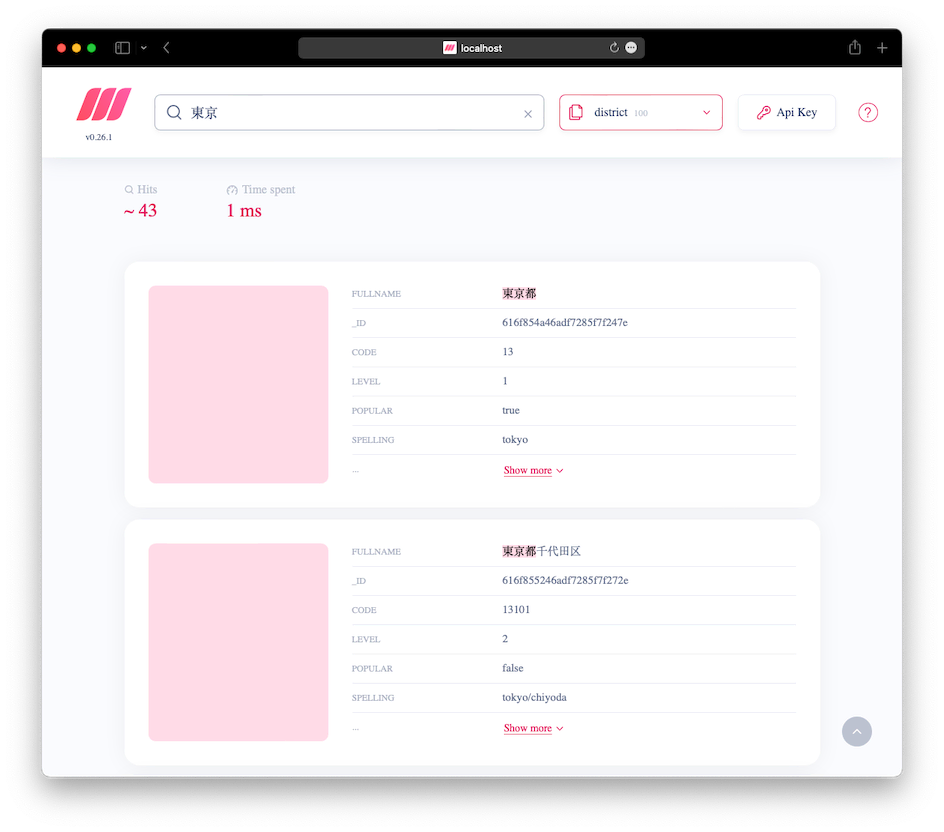
这里输入前面章节的获取 API Keys,然后就可以查看所有的索引,以及在索引下测试搜索功能。
总结⌗
Meilisearch 确实很小巧,也很强大,后面如果有遇到坑也会继续记录和分享,最近有看到一个基于 C++ 开发的搜索引擎——Typesense。又有折腾的素材了!
I hope this is helpful, Happy hacking…