使用 MongoShake 实现 MongoDB 数据同步

需求⌗
我们的团队需要将我们的中国 MongoDB 数据库的数据同步到日本的数据库中,因为国内的服务会产生数据,而日本那边的业务则是用这些数据做分析。有些情况下可能还需要将日本那边修改的数据再同步回国内数据库。
调研了市面上所有 MongoDB 数据库的同步工具,目前就只有 MongoShake 符合我们的要求。
简介⌗
MongoShake 是阿里巴巴基于 Go 实现的一个 MongoDB 数据同步的开源项目,基于mongodb oplog的集群复制工具,可以满足迁移和同步的需求,进一步实现灾备和多活功能。已经在 MongoDB 云版数据库中得到了广泛应用,但是很多特性只有阿里云的 MongoDB 数据库才能使用,而自己采用开源版本搭建的数据库则无法支持,这是因为阿里云对 MongoDB 的核心做了修改。
MongoShake 支持多种方式实现数据的同步,其中有 RPC、TCP、File、Kafka、自定义的 API 以及 Direct。我们主要采用的是 Direct 这种方式同步,获取源端的 Oplog 然后直接写入目标数据库的对应 NameSpace 中。
MongoShake 支持的同步模式有:全量加增量、全量和增量,可以按需修改配置文件来实现不同的同步模式(模式选择上有些坑后面会讲到)。
同时支持黑白名单的设置,用于排除某些不需要同步的数据库或集合,或者仅同步指定的数据库或集合。
安装⌗
访问MongoShake的 Release 页面下载编译后的可执行程序。
解压后会得到如下文件:
tar -zxvf mongo-shake-v2.6.5.tar.gz
x mongo-shake-v2.6.5/
x mongo-shake-v2.6.5/receiver.linux
x mongo-shake-v2.6.5/mongoshake-stat
x mongo-shake-v2.6.5/receiver.darwin
x mongo-shake-v2.6.5/collector.linux
x mongo-shake-v2.6.5/comparison.py
x mongo-shake-v2.6.5/receiver.conf
x mongo-shake-v2.6.5/stop.sh
x mongo-shake-v2.6.5/collector.windows
x mongo-shake-v2.6.5/collector.conf
x mongo-shake-v2.6.5/receiver.windows
x mongo-shake-v2.6.5/collector.darwin
x mongo-shake-v2.6.5/start.sh
x mongo-shake-v2.6.5/hypervisor
配置⌗
编辑 collector.conf 文件,主要修改如下配置项:
sync_mode⌗
用于配置同步方式,前面也提到了三种同步模式,如果目标库时新库,第一次需要做全量同步的,可以选择 all 或者 full。
二者的区别是,all 会先进行全量同步,完成后自动切换为增量同步,这里有个坑,就是配置文件里一直都是 all,但是如果下次应为某种原因导致 MongoShake 进程退出了,你再次手动重启时,切记要将同步模式修改为增量模式,也就是 incr。
如果全量同步时选择的是 full ,而不是 all 模式,那么在第一次全量同步完成后,进程将会自动退出。在启动进程前,切记将同步模式修改为增量模式,也就是 incr。
否则再次启动,将会删除目标数据库的数据,重新进行全量同步。
mongo_urls⌗
源数据库的连接地址,如:
mongodb://username:[email protected]:20040,127.0.0.1:20041。
tunnel⌗
同步数据的方式,我们这里用最简单的直接同步到目标数据库——direct。
tunnel.address⌗
这里配置目标数据库的地址,如:
mongodb://username:[email protected]:20040,127.0.0.1:20041。
incr_sync.oplog.gids⌗
如果是双向同步,且两端都是阿里云的 MongoDB 服务,那么可以向阿里云申请开启 GID 防止环形复制。
开启后在阿里云 MongoDB 的 oploag 中会看到用于标记来源的 gid。
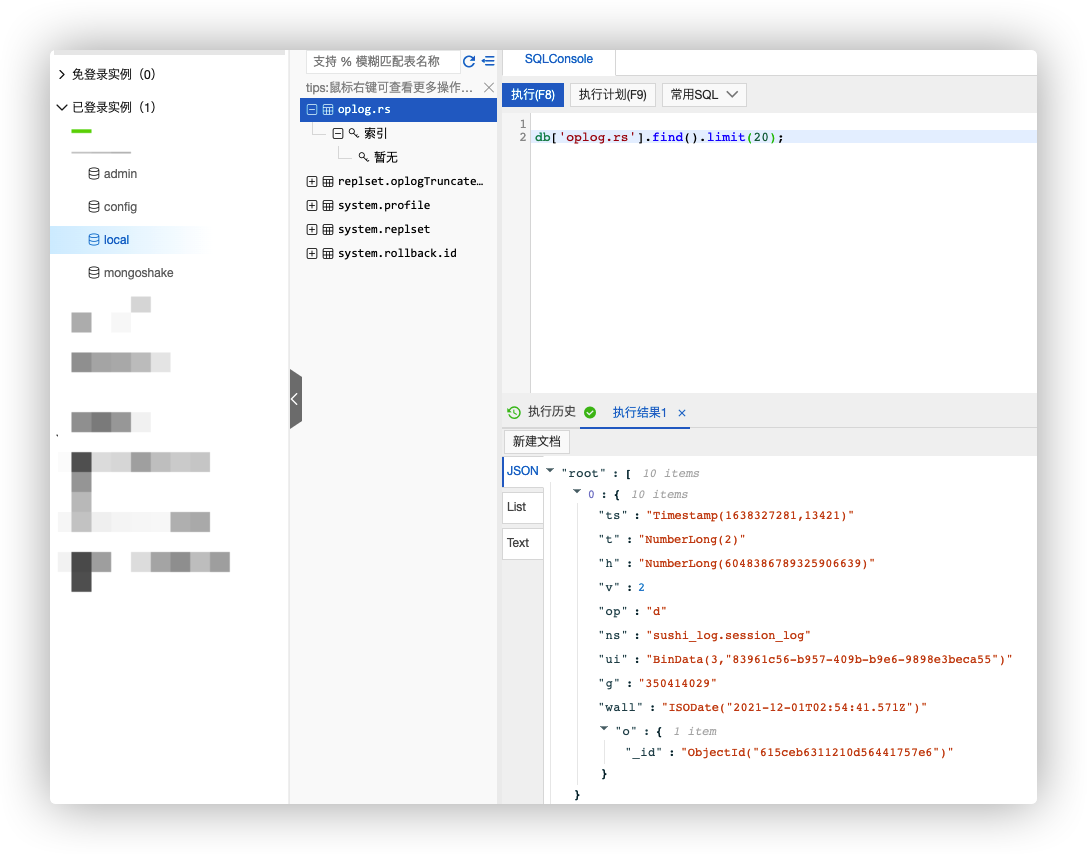
checkpoint.storage.url⌗
配置用于保存同步位置信息的数据库连接,如果没有设置,则默认在源端数据库中创建一个数据库和集合。
checkpoint.storage.db⌗
配置存放 checkpoint 数据的数据库名称,默认为 mongoshake。
checkpoint.storage.collection⌗
配置存放 checkpoint 数据的集合名词,默认为 ckpt_default。可以通过查看这个集合中的数据,知道当前 Oplog 同步到哪个时间点了,避免造成 Oplog 的大量堆积,或被覆盖,造成数据无法同步会丢失!
checkpoint.start_position⌗
这个配置是用于设置读取源数据库 Oplog 时间点的,如果配置了一个时间点不是 1970-01-01T00:00:00Z,且在源端数据库的 Oplog 中无法找到对应的记录,那么同步服务将会启动失败!这个参数非常重要,尤其是在同步服务发送故障而停止后,需要再次重启的时候。
举个例子:⌗
我司的数据库最近因访问量的增长,数据库的磁盘空间捉襟见肘。于是我们考虑删除一部分旧的访问数据(这也是一个坑),如果是删除某个时间段之前的数据,这种方式只能一条条执行,如果数据量大的话,将会产生大量的 Oplog。
我们的一个节点就是因为这种原因导致,短时间内产生大量 Oplog,而 Oplog 的空间是磁盘总大小的 %5,所以就导致了 Oplog 被覆盖,而当同步服务读取 Oplog 时找不到,就出现了错误,服务无法正常运行。
还有一点就是我们尝试重启同步服务时,没有修改配置文件中的 sync_mode 为 incr。最终导致生成环境的目标数据库,被删库。
好在我们的数据库有快照,且时间间隔不算太久。
总结⌗
如果 MongoShake 因为某种原因而停止了,再次启动前,切记检查一下同步模式,避免目标数据库被删库。然后如果启动失败,可以访问阿里云的数据库管理后台,查看最早一条 oploag 的时间,也就是上面截图中的 ts 字段,并将该时间戳专为 UTC 时区的时间,修改 checkpoint.start_position 配置项的值为哪个时间点。
I hope this is helpful, Happy hacking…