MongoDB Series - Related Concepts

Advantages of NoSQL Compared to Traditional SQL⌗
- Significantly improved development efficiency
- Excellent horizontal scaling capability
Compared to traditional relational databases, MongoDB uses an object-like data structure—BSON—to store data, which is very developer-friendly and simplifies database schema design and ORM layer coding work for developers.
If you are a developer, MongoDB allows you to spend less time on the database and focus more on business programming. If you are a DBA, it can effectively solve database performance, high availability, and horizontal scaling pain points. If you are an architect, MongoDB’s flexible design patterns allow you to quickly respond to changing business requirements!
Object ID⌗
For people accustomed to traditional relational databases, when first encountering MongoDB, it feels strange to have a mysteriously generated _id field. When I first started using MongoDB, I was also confused and still habitually kept auto-increment IDs similar to MySQL. After understanding the principles behind Object ID, I gradually replaced auto-increment IDs with Object IDs. This is because, in a distributed environment, traditional auto-increment IDs are both time-consuming and labor-intensive. Of course, there’s also UUID, but UUID has a significant issue with sorting.
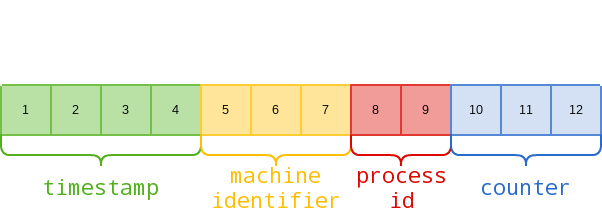
Object ID is a 12-byte BSON type data. A complete ID should contain four segments of data:
- Timestamp
- Server identity
- Process ID
- Auto-increment counter (initial value is random)
Document⌗

A document can be understood as a single record in a traditional relational database. In MongoDB, it’s called a Document, and MongoDB uses BSON to store documents. This structure is similar to JSON but has differences—it can be understood as a superset of JSON.
BSON defines stricter data types than JSON, such as NumberInt, ISODate, etc. When inserting a document, MongoDB generates an Object ID for it, equivalent to a primary key in MySQL.
Collection⌗

A collection is a group of multiple documents, corresponding to a table in traditional relational databases. However, since MongoDB is a NoSQL or Schemaless database, you don’t need to design a schema and create data tables like in traditional relational databases.
When you insert the first piece of data into a Collection, the collection is automatically created, and the structure can differ between Documents. Of course, this Schemaless design approach has pros and cons, depending on how you use it.
I’ve also heard many people complain that it’s too flexible, leading to increased code maintenance costs, with developers wasting a lot of mental effort dealing with Document field validation and compatibility.
Perhaps based on this consideration, MongoDB also provides Schema Validation functionality. With it, you can configure Schema Validation for Collections containing Documents that need structure validation. This way, when a Document is written, if it doesn’t conform to the Schema Validation definition, the data cannot be written, and an exception is thrown.
Replication⌗
To achieve high database availability and avoid service unavailability due to single-node failures, MongoDB uses ReplicaSet to implement high availability. In a ReplicaSet cluster, nodes primarily have the following two roles:
- Primary
- Secondary
The Primary node can be used for both reading and writing, and data can only be written to the Primary node in a replica set. Secondary nodes are only used for read operations. However, Secondary nodes also have some settings that can prevent them from being elected as Primary nodes, and hidden nodes can be configured so that services or application layers cannot send query requests to hidden nodes.
However, hidden nodes can still synchronize data from the Primary node. Additionally, hidden nodes can participate in voting to elect a Primary node. You might wonder what their purpose is—just for voting? That would be a waste of disk and memory resources.
In fact, the main purpose of hidden nodes is for specific tasks such as reporting and database backups. This ensures that some read-only operations at the operations level do not affect online services and applications.
Oplog⌗
As mentioned earlier, write operations are handled by the Primary node. How is data synchronization between nodes implemented? It’s through Oplog. Before writing data to the Primary node, the write operation and the data to be written are recorded in the MongoDB Oplog collection, and then an independent process monitors the Oplog and synchronizes it to other Secondary nodes.
By default, the size of the Oplog collection is set as a percentage of the total disk size. When the data in the Oplog collection reaches the limit, new data will overwrite old data. Therefore, when a large amount of Oplog is generated on the Primary node in a short period, it may cause data inconsistency in Secondary nodes because the Oplog hasn’t been synchronized before being overwritten!
When deleting a large amount of data from a Collection, remember to consider the size of the Oplog collection!
Sharding⌗
While the replica set approach solves the database high availability problem, as business grows, data volume also grows explosively. At this point, sharding is needed to achieve horizontal scaling and increase database disk space. This approach is actually a more complex version of ReplicaSet, where each shard is a ReplicaSet.
The core lies in MongoDB’s architectural layering, using Config Servers to store shard data routing information, and mongos to forward data routing to the backend Shard clusters.
Misconceptions⌗
Many people have certain misconceptions about MongoDB, such as:
- MongoDB cannot achieve the functionality of relational databases
- MongoDB does not support transactions
- MongoDB cannot ensure document structure consistency
MongoDB is not incapable of implementing data associations; rather, it weakens the associated data structure and simplifies the complexity of data associations through embedded documents. If you insist on using it like a relational database, you can!
MongoDB provided transaction support in version 4.x, but transactions have a significant impact on performance, especially in high-concurrency scenarios. So it’s better to implement through architectural design if possible, rather than through transactions!
For the third case mentioned above, you can use Schema Validation to implement document structure constraints!
Conclusion⌗
This article has briefly introduced the advantages of MongoDB as a NoSQL database compared to traditional relational databases. It’s not hard to see that MongoDB can both attack and defend—from a developer’s perspective, MongoDB greatly improves development efficiency.
Of course, MongoDB is much more complex than described in this article, which won’t be elaborated on further here. I will continue to publish notes and personal insights on the use and maintenance of MongoDB in the future!
I hope this is helpful, Happy hacking…