MongoDB 系列之相关感念

NoSQL 对比传统 SQL 的优势⌗
- 开发效率显著提升
- 卓越的横向扩展能力
相比于传统关系型数据库,MongoDB 采用了类似对象结模型的数据结构——BSON 来存储数据,这对于开发人员来说非常友好,从而简化了开发人员的数据库模式设计和 ORM 层编码的工作。
如果你是开发人员,那么 MongoDB 可以让你化更少的时间在数据库上,更专注于业务编程。如果你是 DBA 它可以很好的解决数据库高性能、高可用和横向扩展的痛点。如果你是架构师,那么 MongoDB 的灵活设计模式,可以让你快速响应业务需求的变化!
Object ID⌗
对于习惯了传统的关系型数据库的人来说,刚接触 MongoDB 时给人的感觉就是为什么要莫名奇妙的生成一个 _id 的字段。在我刚开始使用 MongoDB 时我也很不解,依然会习惯性的保留类似 MySQL 的自增 ID。后来了解了 Object ID 的构成原理后,才逐渐的使用 Object ID 替代了自增 ID。因为对于分布式环境来说,传统的自增 ID 是既费时又费力的方案。当然还有 UUID,但是 UUID 也会存在一个较大的问题就是排序。
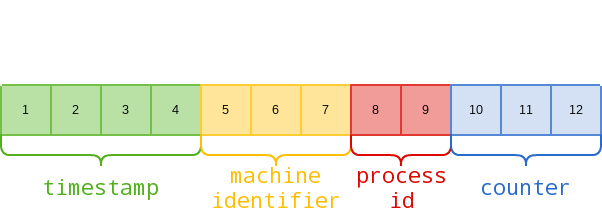
Object ID 是一个 12 字节的 BSON 类型数据,一个完整的 ID 应包含四段数据:
- 时间戳
- 服务器身份标识
- 进程标识
- 自增计数器(初始值为随机)
Document⌗

所谓文档,可以理解成传统关系型数据库中的一条数据,在 MongoDB 中被成为 Document——文档,MongoDB 使用 BSON 的方式来存储文档,这种结构类似 JSON,但又有不同之处,可以理解为 JSON 的超集。
因为 BSON 定义了比 JSON 更加严格的数据类型,例如 NumberInt, ISODate 等。在插入文档的时候,MongoDB 都睡为其生成一个 Object ID,相当于 MySQL 中的主键。
Collection⌗

所谓集合,就是多个文档的集合,这个概念对应传统关系型数据库中的表。然而因为 MongoDB 是 NoSQL 或者说是 Schemaless 的数据库,所以你并不需要像传统关系型数据库那样,设计 Schema 并创建数据表。
当你在某个 Collection 中插入第一条数据的时候,集合就自动创建了,并且 Document 之间的结构可以存在差异。当然这种 Schemaless 的设计方式有利有弊,要看你如何使用它。
我也听过很多人抱怨它太过于灵活以至于导致代码的维护成本增高,开发者会浪费大量的心智去处理 Document 的字段判断和兼容上。
也许是基于这种考虑吧,MongoDB 也提供了 Schema Validation 的功能,有了它你可以对需要验证 Struct 的 Document 所在的 Collection 配置 Schema Validation。这样当 Document 被写入是,如果不符合 Schema Validation 的定义,那么将导致数据无法写入,并抛出异常。
Replication⌗
为了实现数据库的高可用,避免因单节点故障导致服务的不可用,MongoDB 采用 ReplicaSet 的方式实现数据库的高可用。在 ReplicaSet 集群中,节点主要有以下两种角色:
- Primary
- Secondary
其中 Primary 节点可用于读和写,并且副本集中只能将数据写入 Primary 节点,Secondary 仅用于读操作,但是 Secondary 节点也存在一些设置,通过这些设置可以让 Secondary 不能被选为 Primary 节点,并且可以设置隐藏节点,这样对于服务或应用层将无法发送查询请求到隐藏节点上。
但是隐藏节点依然可以从 Primary 节点同步数据,另外隐藏节点还可以参与投票选举 Primary 节点,也许你会好奇它存在的意义是什么,仅仅是为了投票吗?那么白白的浪费了磁盘和内存资源。
其实隐藏节点的主要作用是一些特定的任务,如报告,和备份数据库。这样可以保证运维层面的一些只读操作不会影响到线上的服务和应用。
Oplog⌗
前面说到写操作都由 Primary 节点负责,那么节点间的数据同步如何实现呢,就是通过 Oplog 来实现,在 Primary 节点写入数据之前,现将写操作以及写入的数据,记录在 MongoDB Oplog 集合中,然后由独立的进程监控 Oplog 并同步到其他 Secondary 节点。
默认情况下 Oplog 集合的大小是按总磁盘大小的百分比来设置的,当 Oplog 集合的数据达到限制时,会用新的数据覆盖掉旧的数据,所以当在 Primary 节点上短时间产生大量 Oplog 可能会导致 Secondary 节点数据不一致,因为 Oplog 还没有来得及同步,就被覆盖了!
如果要大量删除某个 Collection 的数据时,切记要考虑 Oplog 的集合大小!
Sharding⌗
副本集的方式虽然解决的数据库的高可用问题,但是随着业务的增长,数据量也爆炸式的增长,这时候就需要通过分片来实现横向扩展,从而提高数据库的磁盘空间。而这种方式其实就是更复杂版的 ReplicaSet,每个分片都是一个 ReplicaSet。
而核心在于 MongoDB 对于架构的分层,使用 Config Server 存储分片的数据路由信息,mongos 用于转发数据路由到后端的 Shard 集群上。
误解⌗
很多人对 MongoDB 存在一定的误解,例如:
- MongoDB 无法做到关系型数据库的功能
- MongoDB 不支持事物
- MongoDB 无法保证文档结构一致性
MongoDB 并不是不能实现数据的关联,而是弱化了数据的关联结构,通过内嵌文档的方式简化了数据关联的复杂性,如果你非要把它当成关系型数据库来用也是可以的!
MongoDB 在 4.x 版本中提供了事物的支持,但是事物对于性能的影响是很大的,尤其是高并发的场景,所以能通过架构设计实现的,最好不用通过事物来实现!
第三种情况上面有提到,可以使用 Schema Validation 来实现文档的结构约束!
总结⌗
通过本文概要的介绍了 MongoDB 作为 NoSQL 与传统关系型数据库对比的优势,不难发现 MongoDB 进可攻退可守,从开发者角度来说 MongoDB 极大的提高了开发效率。
当然 MongoDB 远比本文描述的要复杂的多,这里就不再赘述,后面会陆续发布关于 MongoDB 的使用和维护笔记以及个人心得!
I hope this is helpful, Happy hacking…